
Claude looks like a $20 decision and behaves like a capacity decision. The plan you pick does not change which model you talk to nearly as much as it changes how long you can keep talking before the session stops, and every surface you use draws from the same budget.
That is the part most reviews leave out, and it is the part that decides whether a team stays productive in month two.
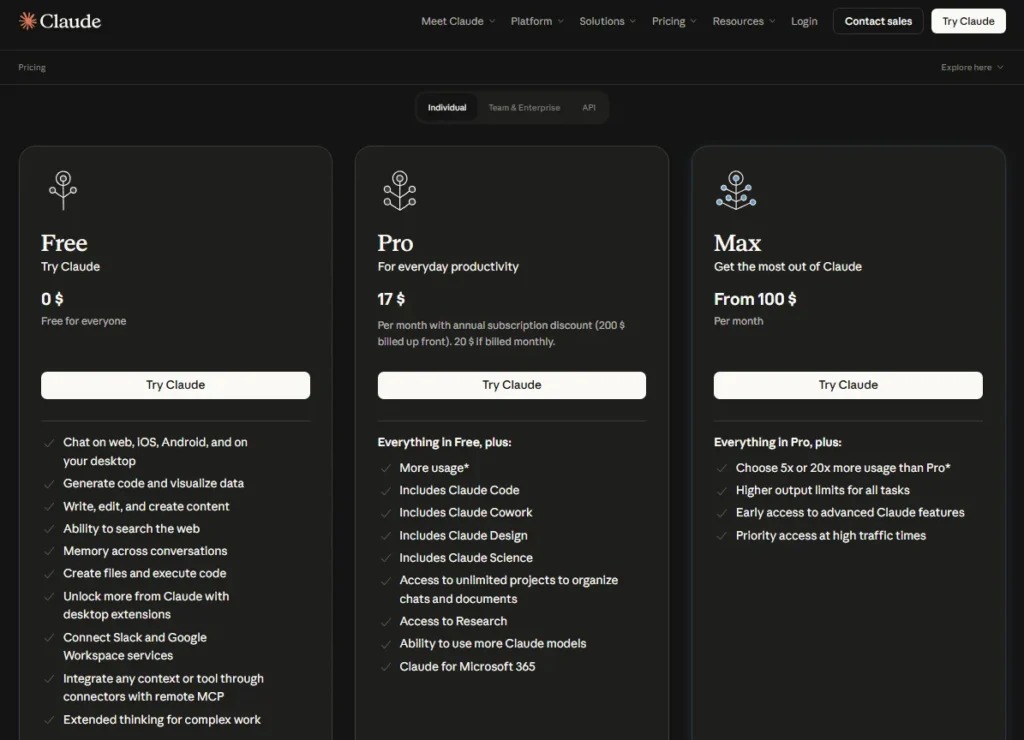
My short verdict: Claude is one of the strongest paid options for long-document work, editorial drafting, and agentic coding, especially when those workflows matter more than native image generation or fixed usage quotas. Pro at $17 per month on annual billing is the correct starting point for one person.
Teams should buy mixed seats rather than uniform ones.
Regulated buyers should treat Claude Cowork as a separate approval item, not a bundled feature.
Quick Verdict
| Quick verdict | Assessment |
|---|---|
| Best for | Individual writers, analysts, and developers working long documents and repositories |
| Not ideal for | Teams needing predictable fixed quotas or native image generation in chat |
| Starting price | $0 Free, $17 per user/month on Pro annual billing ($200 billed up front) |
| Practical plan | Pro for one user, Team with mixed seats for 2 to 150 people |
| Free plan | Yes, with capped projects and one custom remote connector |
| Setup difficulty | Low for chat, moderate for Projects and Claude Code, high for Enterprise governance |
| Main strength | Up to a 1M-token context window on Opus 5 and Sonnet 5 paid-plan chats, plus 500 MB uploads and PDFs to 1,000 pages |
| Main limitation | One shared usage pool across chat, desktop, mobile, and Claude Code |
| Best alternative | ChatGPT for native image generation, Gemini for Google Workspace shops |
Source: Anthropic official pricing page and plan documentation, checked July 25, 2026.
This review sits in the same category as the best AI chatbots shortlist, and it assumes you already know what generative AI does at a basic level.
How This Review Was Researched
This Claude review is based on Anthropic’s official pricing page, help-center documentation, model release notes, connector and Cowork guidance, and labeled third-party review patterns. Pricing, plan limits, model access, and seat minimums were checked on July 25, 2026.
Claude was assessed against the same buyer criteria applied to every assistant on this site: usable entry price, plan-gated workflows, usage ceilings, file and document handling, integration reach, administrative control, and switching cost.
Greater weight went to the factors that change a purchase order rather than a feature list: where the advertised price stops matching the practical budget, which workflows stop working at a plan boundary, and what a finance or security reviewer will question. Vendor positioning and affiliate relationships did not influence the assessment.
Claims that official sources did not support were excluded, and third-party sentiment is labeled as such wherever it appears. Where two official pages disagree, both positions appear with the date checked, and promotional API rates are labeled separately from standard rates.
What Claude Is in July 2026
Claude is Anthropic’s assistant and model platform, reachable through chat on web, desktop, and mobile, plus Claude Code in the terminal, Claude Cowork for delegated multi-step work, Claude Design, and Claude Science. The same subscription covers all of them on paid plans.
The model lineup moved twice in eight weeks. Anthropic announced Claude Sonnet 5 on June 30, 2026, and Claude Opus 5 on July 24, 2026, one day before this review was checked.
Fable 5 is the newer and more expensive tier, and its plan treatment is where buyers get surprised. Paid plans gained access from July 20, 2026, but access does not mean included.
That release cadence is why several Claude reviews ranking on July 25, 2026 are wrong rather than merely dated. Any review with a pricing snapshot from late 2025 or early 2026 predates Sonnet 5, Opus 5, Fable access rules, and the current Enterprise seat model.
Day 1: What Setup and Access Involve
Chat access needs an account and nothing else. The Free plan now covers web, iOS, Android, and desktop chat, code generation, file creation with code execution, memory across conversations, web search, extended thinking, and one custom remote connector built on MCP.
That Free tier is genuinely usable for evaluation, which matters because Anthropic publishes no message count for it. Projects are capped on Free, and the paid plans describe project access as unlimited.
Setting up Claude Code adds a real step. It is included in every paid plan and runs in the terminal or a supported development environment, and per Anthropic’s Claude Code models and usage documentation it consumes the same subscription allowance as chat.
The migration question is where Day 1 gets more expensive than it looks. Anthropic ships an experimental memory import under Settings then Memory for Free, Pro, Max, and Team accounts, and it produces a work-focused memory summary from an export file.
Memory import is not account migration, and the distinction is worth budgeting for. The documentation states that imported items are not always fully incorporated, so anything load-bearing needs manual review after the import.
Data export is a separate mechanism with a separate boundary. Individual Free, Pro, and Max users request an export of account information and chat history from web or desktop, receive an emailed link that expires after 24 hours, and cannot import that export into another personal Claude account.
Organizations get a better deal here than individuals. Anthropic documents a Team to Enterprise migration path and an option to migrate accounts using your own domains, so the hard ceiling applies to personal accounts rather than company workspaces.
For a switching buyer, I would plan for three manual tasks regardless of plan: rebuilding Projects, re-authorizing every connector, and re-establishing organization settings. None of those transfer with a memory file.
The 30/90-day adoption check
After 30 days, one thing should be true: someone on the team can state which plan boundary they hit first, and how often. If nobody knows, the account is underused or the limits are not being tracked in Settings then Usage.
After 90 days, Projects should hold curated reference material rather than accumulated uploads, and at least one recurring workflow should run through Claude Code, Cowork, or a connector instead of copy and paste. A team still pasting documents into fresh chats at day 90 bought capacity it is not using.
Week 1: Where the Workflows Hold Up
Four workflows carry most of the value, and each one has a documented ceiling worth knowing before you rely on it.
Long-document analysis
A single chat accepts files up to 500 MB, a maximum of 20 files, images up to 8,000 by 8,000 pixels, and PDFs up to 1,000 pages, per Anthropic’s file upload documentation. Those are unusually generous thresholds for a consumer-priced assistant.
Two quieter constraints in the same document matter for document teams. Uploading XLSX requires code execution and file creation to be enabled on the account, and for non-PDF documents Claude extracts text only, so images embedded in a DOCX or PPTX are not read.
The catch sits inside the PDF number. Claude processes text and visuals together only for PDFs of 100 pages or fewer, reads pages 101 through 1,000 as text alone, and rejects files above 1,000 pages.
For anyone reviewing financial filings, contracts with exhibits, or engineering reports, a 400-page document with charts loses the charts.
| PDF length | Documented handling | Practical consequence |
|---|---|---|
| 1 to 100 pages | Text and visuals processed together | Charts, tables, and scanned layouts are read |
| 101 to 1,000 pages | Text only | Visual evidence is silently unavailable |
| Above 1,000 pages | Not accepted | File must be split before upload |
Source: Anthropic Help Center, “Upload files to Claude”, documentation checked July 25, 2026.
The workaround is mechanical: split long PDFs into 100-page segments, or export the decisive charts as separate images. I would build that step into the process rather than discover it mid-analysis.
How much context you get, and from which model
Context is set by the model you select, not by the plan you buy, and that is the detail most Claude reviews get wrong. Anthropic’s paid-plan context article was updated on July 25, 2026, and it separates chat from Claude Code.
In Claude chat on any paid plan, Opus 5 and Sonnet 5 carry a 1M-token context window. Opus 4.8, Opus 4.7, Opus 4.6, and Sonnet 4.6 carry 500K, and every other model falls back to 200K.
| Model selected in Claude chat | Context window on paid plans |
|---|---|
| Opus 5, Sonnet 5 | 1M tokens |
| Opus 4.8, Opus 4.7, Opus 4.6, Sonnet 4.6 | 500K tokens |
| Any other model | 200K tokens |
Source: Anthropic Help Center, how large the context window is on paid Claude plans, checked July 25, 2026.
Claude Code follows different rules. On Pro, Max, Team, and Enterprise, Sonnet 5, Fable 5, Opus 5, Opus 4.8, Opus 4.7, and Opus 4.6 all reach 1M tokens, but Pro users have to enable usage credits to get the 1M window on Opus models.
That last clause is a metered gate wearing a capability label. A Pro subscriber who wants a million tokens of repository context on an Opus model is agreeing to pay usage credits at API rates for it.
One caveat on the official numbers themselves. The plan-comparison table on the pricing page still displayed a flat 200k context for Free through Team and 500k on the Enterprise default model when checked on July 25, 2026, which understates current models in chat; the dedicated context article is the more specific and more recently updated source.
Long conversations also get managed for you. On paid plans with code execution enabled, Claude summarizes earlier messages as a conversation approaches the limit, that summarization does not count against your usage limit, and the full history stays available for reference.
Projects as a knowledge base
Projects hold reference material and instructions that persist across conversations, and project files are capped at 30 MB each. File count is unlimited, but total content has to fit the context window, and project files are processed as text extraction only apart from multimodal PDFs.
Retrieval augmented generation is where official guidance stops agreeing with itself. Anthropic’s dedicated RAG help article states that project RAG is available on all plans, activates automatically near the project context threshold, and expands project capacity by up to 10x.
The general Projects article describes enhanced RAG as a paid-plan feature. Both pages were live on July 25, 2026, and I could not reconcile them from public sources.
If you are planning a Free-tier knowledge base around retrieval, verify it in the account before committing. I would not design a workflow on the more generous reading of two conflicting pages.
Claude Code on a repository
Claude Code is included in all paid plans, which is a real cost advantage against buying a separate coding assistant. It reads and edits repository files under scoped permission and runs bounded tasks in the terminal or IDE.
Its usage comes out of the same pool as everything else, which is the single most expensive detail in this review. A long refactoring session consumes the capacity your afternoon chat work needs.
File creation and connectors
Claude creates and edits files in XLSX, PPTX, DOCX, PDF, and PNG up to 30 MB using code execution, and can save to Google Drive. Text-only Artifacts run to 20 MB, while persistent Artifact storage and MCP capabilities require Pro or higher, and Claude Code Artifacts are documented for Team and Enterprise.
Connectors reach Google Drive, Gmail, Google Calendar, GitHub, Microsoft 365, and Slack, with Team and Enterprise owners controlling enablement and each user authenticating individually. Free accounts get one custom remote connector.
One integration constraint deserves an architecture review rather than a footnote. Remote MCP connectors are reached from Anthropic’s cloud, so an endpoint published only inside a private network or behind a corporate firewall is not reachable.
That single sentence disqualifies a common enterprise plan, which is exposing internal tools to Claude without external ingress. Verify reachability before you scope the project, not after.
Month 1: What Breaks at Scale
Three things break first, and none of them is model quality.
The shared usage pool
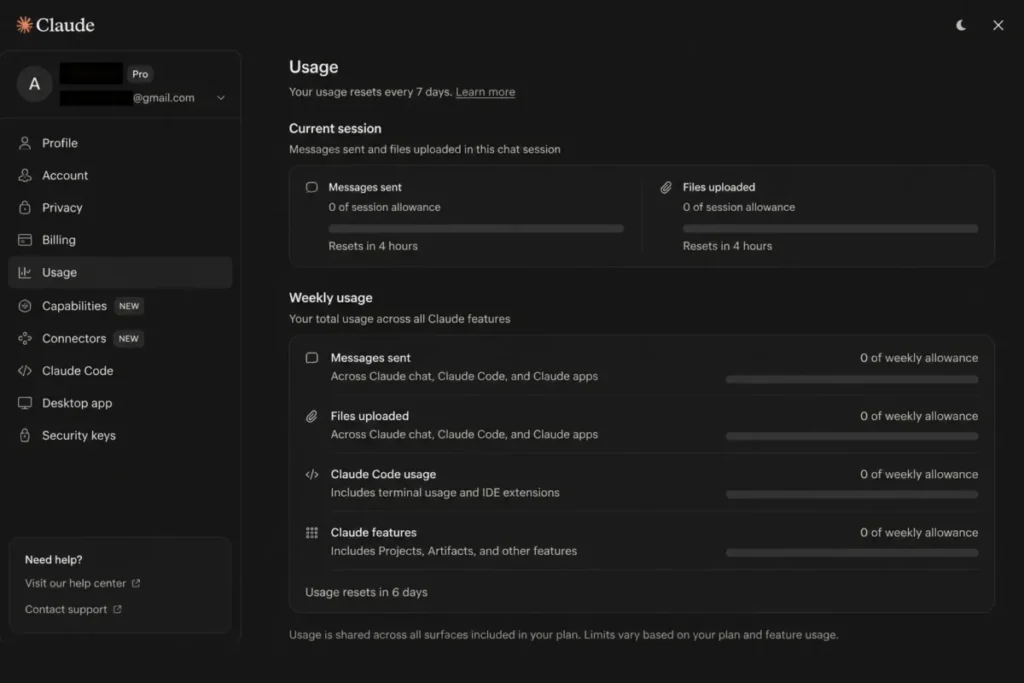
Activity across Claude on web, desktop, and mobile plus Claude Code all draws from the same allowance. Anthropic states this directly in its pricing FAQ and usage documentation.
This is the detail that turns a satisfied Pro subscriber into a frustrated one. Adding Claude Code to an existing chat habit does not add capacity, it divides the same capacity across two demanding uses.
Limits reset on two clocks
Usage resets on a rolling five-hour session window, and paid plans carry weekly limits on top of that, as set out in Anthropic’s usage-limit guidance. Hitting a weekly ceiling is a different problem from hitting a session ceiling, because waiting five hours does not fix it.
There is no published message count on any plan, and that is a documented design choice rather than an omission. Capacity depends on message length, attachments, model choice, feature use, and system capacity.
Anthropic describes relative capacity instead. The Pro plan provides at least 5x more usage per five-hour session than Free, the Max plan provides 5x or 20x more than Pro, Team Standard seats provide more than Pro, and Team Premium seats provide 5x more than Standard.
The Team plan documentation puts precise numbers on the same structure: Standard seats at 1.25x Pro per session with a weekly all-model limit, and Premium seats at 6.25x Pro with two weekly limits, allocated per member. Research mode consumes capacity faster than ordinary chat.
When a limit lands, paid plans offer three responses: wait for the reset, upgrade, or enable usage credits that continue the work at standard API rates. Credit documentation describes monthly caps, auto-reload, usage alerts, and a $2,000 daily redemption ceiling.
Fable 5 bills differently by seat
This is the plan gate most likely to produce an unexpected invoice. Max and Team Premium seats include Fable 5 usage up to 50 percent of weekly limits, while Pro and Team Standard seats consume paid usage credits from the first token.
Selecting the newest model on a $17 plan starts metered spend immediately. I would set a spend cap before letting a team choose models freely.
What recurring user reports emphasize
Public review platforms are consistent about where Claude wins and where it frustrates, and the pattern lines up with the plan mechanics above rather than contradicting them.
Reviewers on G2 repeatedly single out natural-sounding writing, reasoning quality, coding assistance, and comfort with long documents, which are the same workflows the file and context thresholds are built for.
Recurring criticism on G2 and Capterra clusters on restrictive usage caps, over-cautious refusals, a narrower integration ecosystem than the largest competitors, sign-in friction, and uneven feature rollout across surfaces. The caps complaint is the shared-pool mechanic showing up in user language, so treat it as attributed sentiment rather than measured performance.
| Plan or seat | Session capacity | Weekly limits | Fable 5 treatment |
|---|---|---|---|
| Free | Baseline | Not documented as applicable | No access |
| Pro | At least 5x Free | Yes | Usage credits from first token |
| Max 5x | 5x Pro | Yes | Up to 50% of weekly limits |
| Max 20x | 20x Pro | Yes | Up to 50% of weekly limits |
| Team Standard | 1.25x Pro | One all-model weekly limit | Usage credits |
| Team Premium | 6.25x Pro | Two weekly limits | Up to 50% of weekly limits |
| Enterprise | No seat-level cap | None, usage is metered | Billed at API rates |
Context window is deliberately absent from that table because it tracks the model rather than the plan, as the previous section sets out.
Source: Anthropic official pricing page plan-comparison tables plus the Pro, Max, Team, and Enterprise plan documentation, all checked July 25, 2026.
The Enterprise row is the one competitors miss, and it cuts both ways. Enterprise removes seat-level usage limits entirely, but it replaces a predictable subscription with a metered bill.
The Pricing Math Nobody Shows You
Published prices are accurate and incomplete. Here is the full US list as displayed on July 25, 2026.
| Plan | Monthly | Annual billing | Minimum | Usage included |
|---|---|---|---|---|
| Free | $0 | $0 | 1 user | Capped, no published quota |
| Pro | $20 per user | $17 per user/month, $200 up front | 1 user | Yes, with weekly limits |
| Max 5x | $100 per user | Billed monthly | 1 user | Yes, 5x Pro |
| Max 20x | $200 per user | Billed monthly | 1 user | Yes, 20x Pro |
| Team Standard | $25 per seat | $20 per seat/month | 2 seats, max 150 | Yes, 1.25x Pro |
| Team Premium | $125 per seat | $100 per seat/month | Mixes with Standard | Yes, 6.25x Pro |
| Enterprise | Not offered | $20 per seat/month | 20 seats self-serve, 50 sales-assisted | No, all usage at API rates |
Source: Anthropic official pricing page and the Enterprise plan documentation, both checked July 25, 2026. Prices exclude applicable tax.
Two billing details are worth flagging. Pro annual costs $200 up front against $240 across twelve monthly payments, so annual saves $40 and removes the option to stop mid-year.
Max is monthly. Anthropic’s Max help article and pricing FAQ both state that Max 5x and Max 20x bill monthly, while the pricing comparison table labels Max billing as monthly and annual, and no annual Max price is published.
Treat $100 and $200 as monthly figures until Anthropic resolves that labeling.
What ten users cost
The mandatory arithmetic for any team decision, before tax:
| Configuration | Annual cost | Notes |
|---|---|---|
| 10 individual Pro annual seats | $2,000 | Cheapest, but no central billing, SSO, or admin controls |
| 10 Team Standard seats, annual | $2,400 | Adds SSO, central billing, connector admin controls |
| 8 Standard plus 2 Premium, annual | $4,320 | Two heavy users get 6.25x Pro capacity |
| 10 Team Premium seats, annual | $12,000 | Rarely justified across a whole team |
| Enterprise minimum, 20 seats | $4,800 plus all usage | 20-seat floor applies even for a 10-person team |
Source: calculated from Anthropic official pricing page seat rates and documented plan minimums, checked July 25, 2026. Annual figures exclude tax and any metered usage.
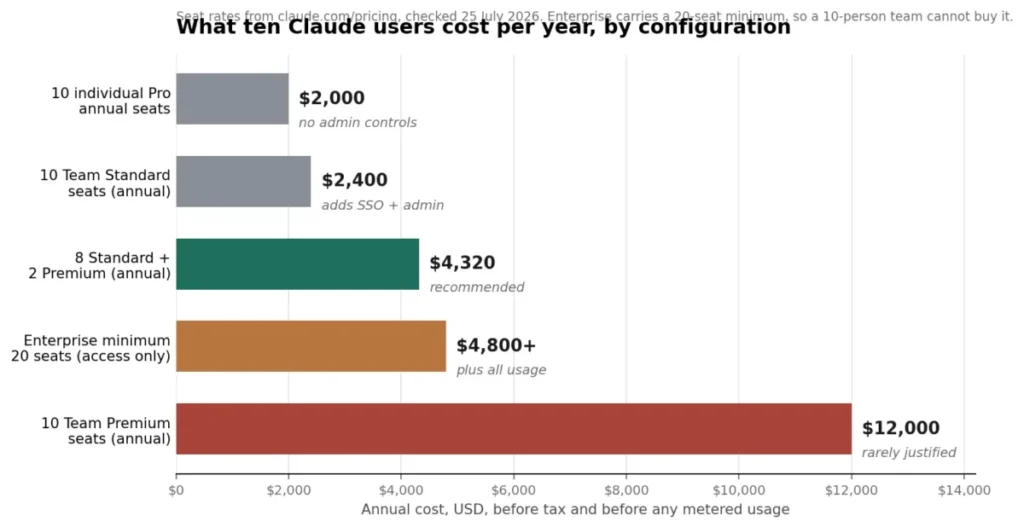
Annual cost of five ten-user configurations. Calculated from Anthropic official pricing page seat rates, checked July 25, 2026.
The mixed configuration is the answer most teams should reach. Paying $100 per seat for ten people to solve a capacity problem two people have is a $7,680 mistake against the mixed option.
That $4,800 Enterprise figure is an access floor, not a budget. It buys zero tokens.
The Enterprise number that is not on the pricing page
Enterprise charges $20 per seat per month, billed annually, and the seat fee covers access only. Every token used in chat, Claude Code, or Cowork bills separately at standard API rates, with no included allowance and no per-seat usage limit, and Anthropic documents the mechanics in how Enterprise billing works.
A ten-person team cannot buy it. Self-serve Enterprise requires a minimum of 20 seats and USD-only payment with credits purchased up front, while sales-assisted Enterprise starts at 50 seats, supports multiple currencies and invoicing, and bills usage monthly in arrears.
Paying by ACH adds a timing risk that catches procurement teams. Plan activation waits for payment to settle, which takes up to five business days, and auto-reload for credits is unavailable on ACH.
One more Enterprise item belongs in any renewal conversation. Organizations still on legacy Chat and Chat plus Claude Code seats, or on seat-based Enterprise plans with Standard and Premium seats, cannot continue those billing models past their next contract renewal, and will move to the single usage-based Enterprise seat.
Modeling metered usage
Because Enterprise usage bills at API rates, the API table becomes a budgeting tool rather than developer trivia. Current published rates per million tokens are Fable 5 at $10 input and $50 output, Opus 5 at $5 and $25, Sonnet 5 at $2 and $10, and Haiku 4.5 at $1 and $5.
Sonnet 5’s rate is promotional, and its standard price is $3 input and $15 output per million tokens once the introductory period ends on August 31, 2026. The same workload renews at 50 percent more with no change on your side.
Promotional API rate re-verified on the publish date: 2026-07-25. Source: Anthropic official pricing page, API section.
Two multipliers stack on top. US-only inference bills at 1.1x for input and output, and Opus 5 fast mode bills at 2x standard pricing.
Tool use is metered separately from tokens, and this is where estimates drift. Web search bills $10 per 1,000 searches, code execution provides 50 free hours daily per organization and then $0.05 per hour per container, and Managed Agents bill $0.08 per session-hour of active runtime, with the full breakdown in the platform pricing documentation.
A research-heavy Enterprise deployment can spend more on searches and containers than on tokens. If you need predictable monthly cost, Team is the plan that provides it, and Enterprise is the plan that does not.
Anthropic’s plan structure changes often enough that I keep a separate Claude pricing guide current, and understanding how API rates apply matters more here than on any competing assistant.
The renewal question
Before an Enterprise renewal, a buyer should be able to answer one question with data: what did usage cost per active user last quarter, and which workflow drove it? Without that number, the next contract is a guess with a 20-seat floor attached.
Security, Support, and Admin Controls
The administrative gap between Team and Enterprise is wide and well documented, which makes qualification straightforward.
| Control | Team | Enterprise |
|---|---|---|
| SSO and domain capture | Yes | Yes |
| Central billing, RBAC, connector admin controls | Yes | Yes |
| Usage analytics, org-wide skills deployment | Yes | Yes |
| SCIM provisioning | No | Yes |
| Audit logs | No | Yes |
| Compliance API | No | Yes |
| Custom data retention controls | No | Yes |
| Customer-managed encryption keys | No | Yes |
| US-only inference | No | Yes |
| Network-level access control and IP allowlisting | No | Yes |
| HIPAA-ready configuration with BAA | No | Available to eligible organizations |
Source: Anthropic official pricing page security-and-administration comparison and the Enterprise plan documentation, checked July 25, 2026.
If your security review requires SCIM deprovisioning or audit logs, Team is disqualified. That is a clean line, and it is the fastest way to end an internal debate about saving money on seats.
Cowork is the item that needs its own approval
Claude Cowork is available on Pro, Max, Team, and Enterprise, which changes the governance question from whether to deploy it to whether individual accounts already have it. Anthropic’s Cowork guidance for Team and Enterprise plans documents execution contexts, admin controls, and monitoring.
The auditability position is unambiguous, and it is the single most important fact for a security reviewer. Cowork activity is not captured in Claude audit logs, the Compliance API, or centralized data exports, and that exclusion is not a plan gate Enterprise money solves.
The Compliance API now covers activity feed events, chat data, file content, and audit-log events across Claude deployments. Cowork sits outside it.
Team and Enterprise owners can stream Cowork events through OpenTelemetry instead, covering user prompts, tool and MCP invocations, and file paths touched during a session. Anthropic states directly that this does not replace audit logging, and no events flow at all until an admin configures an OTLP endpoint.
The OpenTelemetry route carries its own privacy exposure worth naming before rollout. Prompt content is included in events by default, tool parameters can carry file paths and command arguments, and user email addresses appear in event attributes, so filtering or redaction belongs at the collector rather than downstream.
A second boundary catches teams that assume network rules cover everything. Organization network egress permissions do not apply to the web fetch tool, web search, or MCPs, including Claude in Chrome, so an egress allowlist is narrower than it sounds.
My read on the July 25, 2026 documentation: for a workflow that has to produce an audit trail, Cowork is a disqualifier rather than a risk to be managed, and OpenTelemetry routed to a SIEM is operational visibility rather than compliance evidence.
The prompt-injection boundary on file creation
Anthropic’s own file-creation documentation carries a warning that belongs in every security review. Malicious instructions hidden in connected or project content can attempt to make Claude exfiltrate data.
That risk scales with connector reach rather than with plan price. Isolating untrusted documents from connected accounts is the practical mitigation, and it is a process control rather than a product setting.
Support is the weakest-documented area of the product. Anthropic operates a public help center and plan-dependent support, and no published response-time commitment or complete onboarding entitlement matrix appears in public sources.
I would ask for both in writing during an Enterprise negotiation rather than assuming a tier includes them.
Claude’s Limitations
Six limitations stand on their own, separate from the pros and cons summary.
Capacity is unpredictable by design. No plan publishes a message quota, and capacity varies with message length, attachments, model, and feature use, which makes capacity planning an estimate rather than a calculation.
Every surface competes for one budget. Chat, desktop, mobile, and Claude Code share a single allowance on subscription plans, so heavy coding directly reduces available chat capacity.
Visual PDF analysis stops at 100 pages. Longer files are read as text only, without warning in the analysis itself.
Free-plan retrieval eligibility is officially contradictory. Two live Anthropic help pages disagree on whether enhanced project RAG applies to all plans or paid plans only.
Cowork produces no compliance-grade audit trail. Cowork activity is excluded from audit logs, the Compliance API, and data exports on every tier, and Anthropic states that the OpenTelemetry alternative does not replace audit logging.
Personal account portability is one-directional. Exported chat history and account data cannot be imported into another personal Claude account, so a personal archive is a backup rather than a migration path.
Native image generation is a separate boundary rather than a limitation of the documented workflow. Claude’s documented media capability is understanding uploaded images and creating business files including PNG output, and public documentation does not describe consumer-style image generation from a text prompt in chat.
Pros and Cons
| Pros | Cons |
|---|---|
| Pro at $17 per user/month annually bundles Claude Code, Cowork, Design, Science, and unlimited projects | Chat, desktop, mobile, and Claude Code draw from one usage pool, so coding shortens chat capacity |
| 500 MB per file, 20 files per chat, and 1,000-page PDFs handle document sets many assistants reject | No published message quota on any plan makes capacity planning an estimate |
| Team mixes $20 Standard and $100 Premium seats, so two heavy users cost $4,320 a year rather than $12,000 | Fable 5 bills as metered credits from the first token on Pro and Team Standard seats |
| Enterprise adds SCIM, audit logs, Compliance API, customer-managed keys, and a 500k default context window | PDFs above 100 pages lose visual processing and are read as text only |
| Enterprise metering removes seat-level caps, so one heavy user does not consume a shared allowance | Cowork activity is excluded from audit logs, the Compliance API, and data exports on every plan tier |
| Documentation publishes exact file, page, connector, and seat thresholds, making fit testable before purchase | Remote MCP connectors are unreachable when an endpoint sits behind a private firewall |
Who Should Use Claude
Individual analysts and writers working long documents. The 500 MB file ceiling, 20-file chats, and a 1M-token window on current models handle contract sets and filings that break lighter tools. Pro at $200 a year is the cheapest route to that capability.
Developers who want coding and chat on one bill. Claude Code is included in every paid plan, so a $17 subscription replaces a separate coding assistant subscription for anyone whose volume fits the session limits.
Small departments with uneven workloads. Team’s mixed seats let two power users run at 6.25x Pro while eight colleagues run at 1.25x, which is the cheapest correct answer for most 10-person groups.
Regulated organizations that can model metered spend. Enterprise supplies SCIM, audit logs, custom retention, customer-managed keys, US-only inference, IP allowlisting, and HIPAA-ready configuration, and removing seat-level usage caps suits uneven heavy workloads.
Who Should Avoid Claude
Teams that need contractually predictable quotas. Variable session limits, weekly ceilings, and no published message count make Claude a poor fit for a workflow with a delivery commitment attached, unless you provision API capacity separately as a fallback.
Buyers who need image generation in the same chat. The documented media workflow covers image understanding and business-file creation, so a design or social team needs a separate generator alongside Claude.
Ten-person companies that need enterprise controls. The 20-seat self-serve Enterprise floor means a small regulated team pays $4,800 a year plus usage for controls it cannot get on Team at any price.
Organizations whose MCP endpoints stay inside the firewall. Anthropic’s cloud must reach a remote MCP endpoint, so an internal-only integration plan fails before it starts.
Compliance teams that require a complete central audit trail. Cowork activity is excluded from audit logs, the Compliance API, and data exports, so no Anthropic-native report can show an auditor what a Cowork session did.
Claude Alternatives
| Alternative | Choose it if | Pricing note |
|---|---|---|
| ChatGPT | You need native image generation in the same conversation and the widest consumer app ecosystem | Free tier plus paid consumer and business tiers |
| Google Gemini | Your team already standardizes on Google Workspace and wants assistance inside Docs, Sheets, and Gmail | Bundled with Google Workspace tiers and sold as consumer subscriptions |
| Microsoft Copilot | Microsoft 365 governance, tenant controls, and existing licensing decide the purchase | Sold as a per-user add-on to Microsoft 365 |
| Perplexity | The main job is sourced web research with visible citations rather than drafting or coding | Free tier plus a paid subscription |
| GitHub Copilot | You want IDE completions for many developers rather than agentic repository work for a few | Per-seat developer and business pricing |
Competitor prices move independently of Claude’s, so treat the pricing column as a routing hint and confirm current rates on each vendor’s own page; the ChatGPT pricing breakdown tracks the closest substitute.
For a fuller side-by-side, the ChatGPT review, the Gemini review, and the Perplexity review each cover plan gates in the same detail applied here. Getting more from any of them depends on prompt engineering discipline more than on the subscription tier, and teams building a publishing workflow should also look at dedicated AI content creation tools.
Final Verdict: Keep It or Kill It?
Keep it, with the plan chosen by interruption cost rather than by feature list. That is the short answer this Claude review has been building toward, and the plan matters more than the verdict.
For one person, Pro is the right purchase at $200 a year. It includes Claude Code, Cowork, Design, Science, unlimited projects, and Research, and the only reason to leave it is repeated interruption.
Move to Max only after documenting how often Pro limits stop the work. At $1,200 or $2,400 a year, Max 5x and Max 20x are rational when a blocked hour costs more than the difference, and irrational as insurance against a limit you hit twice a month.
For a team of 2 to 150, buy Team with mixed seats and assign Premium by measured usage rather than job title. Ten people with two heavy users cost $4,320 a year, and the same team on uniform Premium seats costs $12,000 for capacity eight of them will not use.
For a regulated organization, treat Enterprise as two purchases: $20 per seat per month for access and governance, plus a metered usage bill you have to model. Run a representative pilot, set organization and user spend limits on day one, and get the Cowork audit scope and support commitments in writing before signing.
Kill it in one situation. If your workflow needs a fixed, contractually guaranteed volume of assistant output, no Claude subscription plan provides that, and the honest answer is API capacity with your own rate management or a different vendor.
Frequently Asked Questions
Is Claude worth paying for in 2026?
For sustained document, writing, research, or coding work, yes. Pro costs $200 a year on annual billing and includes Claude Code, Cowork, Design, Science, and unlimited projects.
The Free plan is capable enough to test that fit first, since it includes web search, file creation, memory, and one custom connector.
What is the difference between Claude Pro and Max?
Capacity, not features. Pro costs $17 to $20 per user/month and provides at least 5x more usage per five-hour session than Free.
Max costs $100 or $200 per month for 5x or 20x Pro capacity, plus higher output limits, early feature access, and priority access at busy times.
Both Max options bill monthly.
Does Claude have a free plan?
Yes. Free covers chat on web, iOS, Android, and desktop, code generation, file creation with code execution, memory across conversations, web search, extended thinking, and one custom remote MCP connector.
Projects are capped rather than unlimited, and Anthropic publishes no fixed message count for the tier.
How many files can Claude analyze, and does it read charts inside PDFs?
A chat accepts up to 20 files at 500 MB each, images to 8,000 by 8,000 pixels, and PDFs to 1,000 pages, while project files and generated files are capped at 30 MB.
Text and visuals are processed together only for PDFs of 100 pages or fewer. Pages 101 through 1,000 are read as text alone, so splitting long documents into 100-page segments restores chart and layout analysis.
How large is Claude’s context window?
It depends on the model, not the plan. In Claude chat on any paid plan, Opus 5 and Sonnet 5 give a 1M-token context window, the Opus 4.8, 4.7, 4.6 and Sonnet 4.6 generation gives 500K, and other models give 200K.
In Claude Code, Sonnet 5, Fable 5, and the Opus models reach 1M on paid plans, though Pro accounts must enable usage credits for 1M on Opus.
Does Claude Team include Claude Code?
Yes. Claude Code is included in all paid plans, including both Team seat types, and it draws from the same usage allowance as chat rather than a separate budget.
Standard seats provide 1.25x Pro session capacity and Premium seats provide 6.25x, allocated per member.
What happens when Claude usage runs out?
Usage resets on a rolling five-hour window, and paid plans add weekly limits. When a limit lands you can wait for the reset, upgrade the plan, or enable usage credits that continue work at standard API rates.
Credit settings include monthly caps, auto-reload, and a $2,000 daily redemption ceiling.
How much does Claude Enterprise cost?
$20 per seat per month, billed annually, with all usage billed separately at API rates and no included token allowance. Self-serve Enterprise requires 20 seats minimum and USD payment, while sales-assisted starts at 50 seats with multi-currency and invoicing.
Twenty seats therefore cost $4,800 a year before any usage.
Is Claude safe for business data?
Team provides SSO, domain capture, role-based access, connector admin controls, and central billing, with no model training on your content by default. Enterprise adds SCIM, audit logs, the Compliance API, custom retention, customer-managed encryption keys, US-only inference, IP allowlisting, and HIPAA-ready configuration for eligible organizations.
Source: Anthropic official pricing page security comparison and Enterprise plan documentation, checked July 25, 2026.
Does Claude remember previous conversations?
Yes, memory across conversations is available from the Free plan upward, and an experimental import under Settings then Memory can seed it from an export file.
Imported items are not always fully incorporated, so review the result. Memory does not transfer Projects, files, or connector permissions.
About the author
Macedona is the founder and lead reviewer at SaaS CRM Review, where he has published 175+ in-depth reviews, pricing guides, and comparisons of CRM and SaaS tools. Each review is based on hands-on testing or verified documentation, and every article states clearly which method was used. Pricing and features are checked against official vendor sources, with the verification date noted in the article. Macedona follows a published review methodology and editorial policy. SaaS CRM Review earns affiliate commissions from some links, which never influence ratings or rankings. Read the full affiliate disclosure.



