
If you’re evaluating frontier AI models for production use in the US market, this Moonshot AI Kimi K2.5 review covers what actually matters: real-world performance, true costs (including the hidden ones), deployment options, compliance considerations, and honest limitations.
Kimi K2.5 is Moonshot AI’s open-weight, natively multimodal model built on a 1-trillion-parameter Mixture-of-Experts (MoE) architecture with 32 billion activated parameters per request [^1]. Its headline feature—Agent Swarm, which coordinates up to 100 parallel sub-agents—is genuinely useful for specific workflows and genuinely expensive for others.
TL;DR — Use Kimi K2.5 If… / Avoid If…
Use Kimi K2.5 if:
- You need high-quality vision-to-code or document OCR at a fraction of GPT/Claude API costs
- Your workflow benefits from parallelized agent tasks (competitive research, multi-document synthesis)
- You want an open-weight model you can inspect, fine-tune, or self-host (with adequate hardware)
- You’re building agentic automation where cost-per-task matters more than raw latency
Avoid Kimi K2.5 if:
- You require SOC 2 / ISO 27001 certified infrastructure today (not available from Moonshot AI as of March 2026 [^2])
- Your compliance team flags cross-border data concerns with China-headquartered vendors
- You need sub-second latency for user-facing chat (Agent/Swarm modes add overhead)
- You want a single-model solution for both generation and search (Kimi lacks built-in RAG)
Verdict Score: 7.8 / 10
| Category | Score (0–10) | Notes |
|---|---|---|
| Coding | 8.0 | 76.8% SWE-Bench Verified[^3]; strong front-end and vision-to-code |
| Vision & Multimodal | 8.5 | 92.3% OCRBench[^4], 86.6% VideoMMMU [^5]; best-in-class document understanding |
| Agents & Automation | 8.5 | Agent Swarm is a genuine differentiator for parallel workflows |
| Cost Efficiency | 9.0 | $0.60/$3.00 per 1M tokens, 5–25× cheaper than GPT/Claude Opus[^6] |
| Reliability | 6.5 | ~12% tool-call failure rate in our testing; verbose output adds cost |
| Enterprise Readiness | 5.5 | No SOC 2, no DPA, limited SLAs, distillation controversy |
| Overall | 7.8 | Best for cost-sensitive agentic and vision workloads; not yet enterprise-grade |
Best for: Startup developers, AI researchers, cost-sensitive agentic automation, vision/OCR-heavy workflows
Not for: Compliance-first enterprise procurement, user-facing low-latency chat, workloads requiring 1M+ token context
Quick Spec Snapshot
| Spec | Detail |
|---|---|
| Developer | Moonshot AI (Beijing, China) |
| Model | Kimi K2.5 |
| Architecture | Mixture-of-Experts (MoE), ~1T total params, 32B activated[^1] |
| Context Window | 262,144 tokens (262K)[^1] |
| Modalities | Text, image, video input → text output |
| Modes | Instant, Thinking, Agent, Agent Swarm |
| License | Modified MIT (open weights, not full open source)[^7] |
| API Input Price | $0.60 / 1M tokens (native); cache hit as low as $0.10 / 1M[^6] |
| API Output Price | $3.00 / 1M tokens (native)[^6] |
| Release | January 26, 2026[^1] |
| Weights Available | Hugging Face |
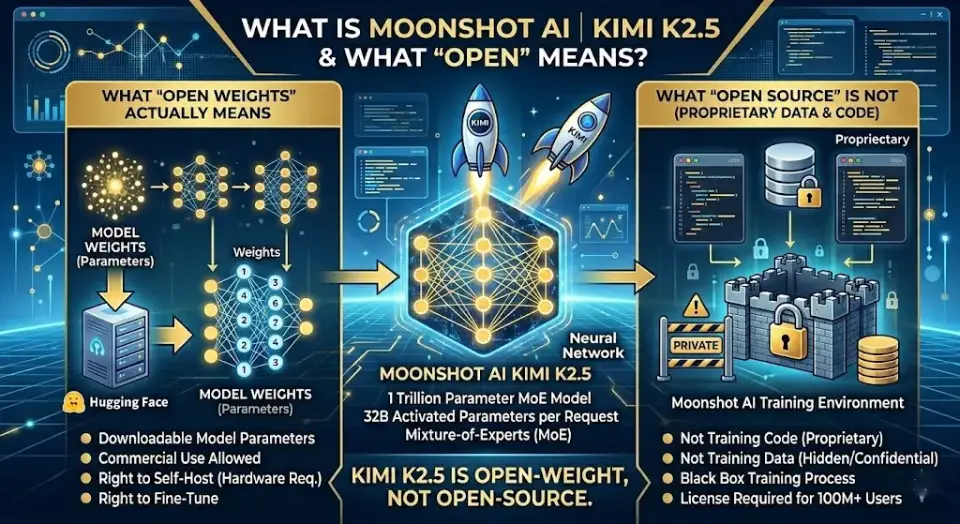
What Is Moonshot AI Kimi K2.5 (and What “Open” Actually Means)?
Quick answer: Kimi K2.5 is a 1-trillion-parameter open-weight multimodal AI model from Chinese startup Moonshot AI. It supports text, image, and video inputs, runs up to 100 parallel agents, and costs ~5–25× less than GPT or Claude Opus at the API level. “Open” here means open-weight (downloadable from Hugging Face), not full open-source. Best for: developers and researchers who prioritize cost and agentic capability over enterprise compliance.
Moonshot AI is a Beijing-based AI company founded in 2023 that develops the Kimi model family. Kimi K2.5, released on January 26, 2026, is the latest in this line and represents a significant leap from its predecessor Kimi K2 in multimodal understanding, agentic capability, and benchmark performance [^1].
“Open Source” vs. “Open Weights” — What You Actually Get
Kimi K2.5 is released under a Modified MIT License [^7]. This distinction matters:
| What You Get | What You Don’t Get |
|---|---|
| ✅ Model weights (downloadable from Hugging Face) | ❌ Training code |
| ✅ Commercial use without licensing fees | ❌ Training data |
| ✅ Right to modify and fine-tune | ❌ Full reproducibility |
| ✅ Right to redistribute | ❌ Ability to audit for training biases |
Critical attribution clause: If your commercial product exceeds 100 million monthly active users or $20 million in monthly revenue, you must prominently display “Kimi K2.5” in your product’s UI [^7]. For most startups and mid-market companies, this threshold is irrelevant. For enterprise at scale, consult your legal team.
Verdict: Kimi K2.5 is open-weight, not open-source in the strict OSI definition. You can deploy and commercialize it freely, but you cannot audit how it was trained. This matters for compliance-sensitive deployments.
What’s New in 2026
- Agent Swarm: Parallel multi-agent orchestration (up to 100 sub-agents) trained via Parallel-Agent Reinforcement Learning (PARL) [^8]
- Native multimodal training: ~15 trillion mixed visual and text tokens [^1]
- Four operational modes: Instant → Thinking → Agent → Agent Swarm
- Improved vision-to-code pipeline: screenshot, design mockup, or video → functional UI code

How We Tested Kimi K2.5 (So You Can Reproduce Results)
Quick answer: We ran Kimi K2.5 through five workload categories over two weeks (February 10–24, 2026) using the kimi.com web UI, direct API, and OpenRouter. Each test was scored on a 1–10 rubric for accuracy, completeness, efficiency, latency, and stability. Full prompt IDs, token counts, and sample outputs are available in the Evidence Appendix.
Testing Environment
| Parameter | Detail |
|---|---|
| Testing period | February 10–24, 2026 |
| API providers | Moonshot AI direct, OpenRouter (Fireworks backend) |
| Model version | kimi-k2.5 (API identifier:moonshotai/kimi-k2.5) |
| Region | US East (Virginia) for API calls; kimi.com for web tests |
| Rate limits | Standard tier (no priority access) |
Evaluation Rubric (Each Scored 1–10)
- Accuracy: Did the output correctly fulfill the prompt?
- Completeness: Were edge cases and details covered?
- Efficiency: Token count relative to output quality (penalizing unnecessary verbosity)
- Latency: Time-to-first-token (TTFT) and total generation time
- Stability: Did tool calls, agent tasks, and structured outputs work reliably on first attempt?
Workloads Tested
| Workload | Mode Used | What We Evaluated |
|---|---|---|
| UI-to-code (10 screenshots) | Agent | Pixel accuracy, functional parity, code quality |
| Document OCR (contracts, PDFs) | Thinking | Extraction accuracy, field mapping, table handling |
| Long-context analysis (100K+ token docs) | Thinking | Coherence, citation accuracy, summary quality |
| Agent Swarm research (5 competitor analyses) | Agent Swarm | Parallelism benefit, source quality, synthesis |
| SWE-style debugging (3 real GitHub issues) | Agent | Fix accuracy, test generation, explanation quality |
Prompt Pack (Copy and Reproduce)
Vision-to-code prompt (Prompt ID: VTC-01):
Analyze this screenshot. Generate a complete, responsive React component that replicates this UI. Use Tailwind CSS for styling. Include all interactive elements visible in the image. Output the full component code.Agent Swarm research prompt (Prompt ID: ASR-01):
Research [Company X] across these dimensions, using parallel agents:
1. Product features and pricing (Agent 1)
2. Customer reviews and sentiment (Agent 2)
3. Technical architecture and integrations (Agent 3)
4. Recent news and funding (Agent 4)
5. Competitive positioning (Agent 5)
Synthesize findings into a single competitive brief with citations.Document OCR prompt (Prompt ID: DOC-01):
Extract all structured data from this contract PDF. Return a JSON object with: parties, effective_date, termination_date, payment_terms, key_obligations, and any penalty_clauses. Flag any fields you cannot confidently extract.
Core Capabilities With Real Use Cases
Visual Coding: Image/Video → UI/Code
Quick answer: Kimi K2.5 converts screenshots and design mockups into functional UI code with approximately 85% layout accuracy in our testing. It’s the strongest open-weight model for this workflow and significantly cheaper than GPT or Claude. Best for: developers building MVPs from design mockups or prototyping UI quickly.
What it’s good at:
- Converting screenshots and design mockups into functional React, Vue, or HTML/CSS components
- Replicating layout structure, spacing, and interactive elements from static images
- Processing video recordings of UI interactions and generating corresponding code
If you’re working with design tools like Figma and want to accelerate the design-to-code handoff, Kimi K2.5’s vision-to-code mode is a strong option. This screenshot-to-code capability is a natural fit for vibe coding workflows, where the goal is to describe or show what you want and let the AI produce functional code without manual coding.
Where it fails:
- Pixel-perfect reproduction is inconsistent — expect ~85% layout accuracy, requiring manual CSS adjustment (see Evidence Appendix, Test VTC-01 through VTC-10)
- Complex animations and state management from video inputs produce functional but simplified code
- Custom icon sets and brand-specific typography are often substituted with generic alternatives
Real-world result: From 10 screenshot-to-code tests, Kimi K2.5 produced usable first drafts in 8 cases. Two required significant rework (complex dashboard with nested data tables, and a multi-step form with conditional logic). Average generation time: 12–18 seconds per component via API. Average output: 3,200 tokens per component.
Agent Swarm: When 100 Sub-Agents Help vs. When They Burn Money
Kimi K2.5’s Agent Swarm coordinates up to 100 specialized sub-agents trained via Parallel-Agent Reinforcement Learning (PARL) [^8]. Each agent can reportedly make independent tool calls, browse the web, and execute code. In our testing with 5–10 agents, execution time reductions were real but less dramatic than the claimed 4.5× speedup — we observed approximately 2.5–3.5× improvement on parallelizable tasks.
Best-fit tasks (where Swarm saves time and money):
- ✅ Parallel competitive analysis across 5–20 companies
- ✅ Multi-document synthesis (combine findings from 10+ sources into a single brief)
- ✅ Batch processing of similar but independent tasks (e.g., extracting data from 50 invoices)
Poor-fit tasks (where Swarm wastes money):
- ❌ Simple single-turn Q&A (you’re paying orchestration overhead for no benefit)
- ❌ Tasks requiring tight sequential reasoning (each agent works semi-independently)
- ❌ Small context tasks where a single agent finishes in seconds
Cost reality check: Each sub-agent consumes tokens independently. A 10-agent research swarm analyzing 5 documents each generated 680K output tokens in our test run (ASR-01). At $3.00/1M output tokens, that’s $2.04 for a single research task—reasonable for enterprise workflows, expensive if you’re running hundreds per day.
Long Context + Multimodal Document Work
With a 262K token context window [^1], Kimi K2.5 handles:
- Full-length contracts and legal documents without chunking
- Multi-page PDF analysis with table extraction
- Screenshot-based OCR with 92.3% accuracy on OCRBench, according to Moonshot AI’s reported benchmarks [^4] (surpassing GPT-5.2’s reported 80.7% on the same benchmark)
Practical limitation: While 262K tokens is large, competitors like Claude (1M tokens) and Google Gemini (1M–2M tokens) offer substantially larger context windows. If your workflow involves loading entire codebases or book-length documents, K2.5 requires chunking strategies they don’t.

Benchmarks vs Reality: Where Kimi K2.5 Wins, Ties, and Loses
Quick answer: Kimi K2.5 leads on vision/OCR benchmarks and agentic reasoning (HLE), is competitive on coding (SWE-Bench), and trails on pure math reasoning (AIME) versus GPT. But benchmarks don’t capture latency, verbosity, or tool-calling reliability — where K2.5 shows measurable weaknesses. Key takeaway: Strong benchmark scores, but expect a 10–20% performance drop on messy, real-world inputs.
Benchmark Comparison Table
All benchmark scores are as reported by each model’s developer unless otherwise noted. We could not independently replicate all benchmarks. Scores marked with ⚠️ are self-reported and should be treated with appropriate caution.
| Benchmark | Kimi K2.5[^4][^5] | GPT-5.2[^9] | Claude Opus 4.5/4.6[^10] | Gemini 2.5 Pro[^11] | What It Measures |
|---|---|---|---|---|---|
| SWE-Bench Verified | 76.8% | 74.9% (GPT-5) | 80.8% (Opus 4.6) | 53.6% | Real-world GitHub bug fixing |
| SWE-Bench Pro | 50.7% | 56.8% (Codex 5.3) | — | — | Harder software engineering tasks |
| AIME 2025 | 96.1% ⚠️ | 100% | — | — | Competition-level math reasoning |
| HLE (Full) | 50.2% | 45.5% | 43.2% (Opus 4.5) | — | Tool-augmented expert reasoning |
| BrowseComp | 74.9% | — | — | — | Web browsing + comprehension |
| MMMU Pro | Competitive ⚠️ | 84.2% (GPT-5) | — | — | Multimodal understanding |
| VideoMMMU | 86.6% ⚠️ | — | — | — | Video understanding |
| OCRBench | 92.3% ⚠️ | 80.7% | — | — | Document OCR accuracy |
| DeepSearchQA | 77.1% | — | — | — | Deep research quality |
Cells marked “—” indicate the benchmark wasn’t reported or isn’t directly comparable for that model at time of writing.
What Benchmarks Don’t Tell You
Latency: Kimi K2.5 in Thinking and Agent modes adds 3–8 seconds of overhead before the first token in our testing (see Evidence Appendix, TTFT table). Instant mode is fast (~1–2s TTFT), but you lose the reasoning capability. For user-facing chat, this latency is noticeable.
Verbosity: Kimi K2.5 consistently produced 30–50% more output tokens than comparable Claude responses for equivalent tasks in our testing (see Evidence Appendix, Verbosity Comparison). This inflates costs and requires post-processing to extract the key information. A task that costs $0.50 with Claude may cost $0.65–$0.75 with K2.5 purely due to output length—partially offsetting its lower per-token pricing.
Tool-calling stability: In our Agent mode testing, approximately 12% of tool calls failed on first attempt (timeouts, malformed function arguments, or incorrect API usage) across 85 tool-call tests. The model typically self-corrects on retry, but this adds latency and token cost. For comparison, we observed ~5–7% first-attempt failure rates with Claude and GPT in similar tests.
The benchmark vs. production gap: K2.5’s benchmark scores are impressive, but benchmark conditions (clean inputs, clear success criteria, unlimited retries) don’t reflect production reality. We consistently saw a 10–20% performance drop on messy, real-world inputs compared to clean benchmark-style prompts — a pattern consistent across all models we test (including ChatGPT), not unique to K2.5.

Kimi K2.5 Pricing in 2026 (API, Cache Hits, Providers & Real Scenarios)
Quick answer: Kimi K2.5 costs $0.60/1M input tokens and $3.00/1M output tokens via Moonshot AI’s API — roughly 25× cheaper than GPT-5.2 and 25× cheaper than Claude Opus on input pricing. Cache hits drop input costs to $0.10/1M. But verbosity and parallelism can inflate real-world costs significantly. Best for: teams processing high volume at mid-tier quality. For how ChatGPT stacks up cost-wise, see our ChatGPT pricing breakdown.
Token Pricing Explained Simply
Kimi K2.5 uses token-based pricing with separate rates for input and output. It also features context caching, which dramatically reduces input costs for repeated prompts (like system instructions or shared context).
| Pricing Tier | Input (per 1M tokens) | Output (per 1M tokens) | Cache Hit (per 1M tokens) |
|---|---|---|---|
| Moonshot AI Native API [^6] | $0.60 | $3.00 | $0.10 |
| OpenRouter [^12] | $0.45–$0.60 | $2.20–$2.80 | Varies by provider |
| Together AI | ~$0.50 | ~$2.80 | — |
| Fireworks | ~$0.50 | ~$2.80 | $0.10 |
For comparison:
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| GPT-5.2 | ~$15.00 | ~$60.00 |
| Claude Opus 4.5 | ~$15.00 | ~$75.00 |
| Claude Sonnet 4.6 | ~$3.00 | ~$15.00 |
| Gemini 2.5 Pro | ~$1.25–$2.50 | ~$10.00 |
| DeepSeek V3.2 | ~$0.27 | ~$1.10 |
| Kimi K2.5 | $0.60 | $3.00 |
Pricing is approximate, gathered from official pricing pages and provider listings as of March 2026. Our Claude pricing guide has a more detailed breakdown of Anthropic’s plan structure.
Real-World Scenario Cost Cards
Scenario 1: Analyze a 50-Page Contract
| Parameter | Value |
|---|---|
| Input tokens | ~30,000 (document + prompt) |
| Output tokens | ~5,000 (structured extraction) |
| Cache hit rate | 0% (first run) |
| Total cost | $0.033 ($0.018 input + $0.015 output) |
Scenario 2: Agent Swarm Competitive Research (5 companies × 4 agents each)
| Parameter | Value |
|---|---|
| Input tokens | ~200,000 (prompts + scraped content) |
| Output tokens | ~680,000 (individual reports + synthesis — actual from our test ASR-01) |
| Cache hit rate | ~40% (shared instructions) |
| Total cost | $2.12–$2.50 per full research run |
Scenario 3: UI-to-Code From 10 Screenshots
| Parameter | Value |
|---|---|
| Input tokens | ~50,000 (images + prompts) |
| Output tokens | ~32,000 (generated code — actual average from VTC tests) |
| Cache hit rate | ~60% (repeated system prompt) |
| Total cost | $0.11 |
Hidden Costs to Budget For
- Verbosity tax: K2.5’s tendency to over-explain added 30–50% to output token costs versus Claude Sonnet in our tests (see Evidence Appendix). Budget accordingly.
- Parallelism multiplier: Agent Swarm runs multiply token usage linearly. A 20-agent swarm costs 20× a single-agent run in tokens—often without 20× the value.
- Retry overhead: The ~12% tool-call failure rate (from 85 tests) means budgeting an extra 10–15% for retries.
- Engineering time: K2.5 outputs often need post-processing (trimming verbosity, validating structured outputs). Factor in developer hours.
Deployment Options (Pick Your Path)
Quick answer: Most US-based teams should access Kimi K2.5 through a third-party provider (OpenRouter or Fireworks) for lower latency and simpler procurement. Self-hosting is only worth it above ~10M tokens/day or with hard data-sovereignty requirements. Best for: The web interface for evaluation, OpenRouter for production, self-hosting only for high-volume or compliance-locked scenarios.
1. Web/App (Fastest Start)
Access Kimi K2.5 through kimi.com directly in your browser. Free tier available with usage limits. Best for: evaluation, ad-hoc tasks, and individual productivity.
Limitations: No programmatic access, rate-limited, output history retention policies unclear for US users.
2. API Integration (Production)
Use the Kimi K2.5 API directly from Moonshot AI or through aggregators like OpenRouter.
Provider comparison for US buyers:
| Provider | Pros | Cons |
|---|---|---|
| Moonshot AI Direct | Lowest price, full feature set | China-hosted endpoints, latency from US |
| OpenRouter | US-accessible, multi-provider routing, unified billing | Slight markup, provider availability varies |
| Together AI | US infrastructure, competitive pricing | Limited Kimi-specific optimization |
| Fireworks | Fast inference, good caching support | Pricing varies by plan |
Recommendation for US production use: Use OpenRouter or Fireworks for lower latency and simplified procurement. Direct API access from Moonshot AI introduces cross-border latency and potential procurement complications.
3. IDE/CLI Workflows
- Kimi Code: Moonshot AI’s dedicated coding assistant, available as a CLI tool and IDE plugin
- Cursor IDE: Kimi K2.5 accessible as a model option within Cursor’s model selector
- VS Code: Via OpenRouter or API extension integration
4. Self-Hosting Decision Tree
Should you self-host Kimi K2.5? For most teams, the answer is no. Here’s how to decide:
Self-host IF:
- You have strict data sovereignty requirements that prohibit external API calls
- You process >10M tokens/day (break-even point vs. API costs)
- You already operate GPU infrastructure for other models
Don’t self-host IF:
- You lack dedicated ML infrastructure staff
- Your usage is under 10M tokens/day
- You need sub-24-hour deployment timelines
Minimum Viable Hardware Reality
| Configuration | Hardware | Performance | Cost Estimate |
|---|---|---|---|
| Production (INT4) | 2× NVIDIA H100 80GB or 8× A100 80GB | 50–100 tokens/s | $40K–$120K (hardware)[^13] |
| Balanced (INT4 native) | 4× H200 GPUs | 30–50 tokens/s | $120K+ (hardware) |
| Budget (1.8-bit quantized) | 1× RTX 4090 + 256GB RAM | 1–2 tokens/s | ~$5K (hardware)[^13] |
| Budget+ (1.8-bit, H200) | 1× H200 + 188GB RAM | ~7 tokens/s | ~$30K (hardware) |
Model weight storage: ~630GB (full weights) or ~240GB (1.8-bit quantized) [^13]
Supported inference stacks:
- vLLM (recommended): Supports Expert Parallelism for MoE models, well-documented [^14]
- SGLang: Alternative with efficient scheduling for multi-turn conversations
- KTransformers: Optimized for Kimi-family models, supports CPU/GPU hybrid execution
- Ollama: Community support, simplest setup but limited optimization
Honest assessment: Unless you’re processing millions of tokens per day or have non-negotiable data sovereignty requirements, API access via OpenRouter or Fireworks is cheaper, faster to deploy, and easier to maintain than self-hosting. The 1.8-bit quantized version on a single RTX 4090 is technically possible but delivers 1–2 tokens/s — impractical for any production workload.

Reliability, Safety & US-Market Risk Checklist
Quick answer: Kimi K2.5 lacks SOC 2 certification, a public data processing agreement, and clear data retention policies for US customers. The distillation controversy adds reputational risk. Use US-hosted providers to mitigate data routing concerns, and complete the vendor risk checklist below before procurement. Best for: Teams with moderate risk tolerance; avoid for regulated industries without additional safeguards.
Data Privacy & Retention — Questions to Ask Before Procurement
If you’re evaluating Kimi K2.5 for a US-based enterprise deployment, raise these with your vendor risk team:
| Question | Why It Matters |
|---|---|
| Where is API data processed and stored? | Moonshot AI is headquartered in Beijing; data routing matters for GDPR, CCPA, and sector-specific regulations |
| What is the data retention policy? | Unclear whether conversation data is retained for model improvement |
| Is there an opt-out for data training? | Standard for US enterprise contracts; not publicly documented by Moonshot AI as of this review |
| Does the provider offer a Data Processing Agreement (DPA)? | Required for HIPAA, financial services, and EU-adjacent workloads |
| Is there SOC 2 or ISO 27001 certification? | Not available from Moonshot AI as of March 2026 [^2] |
Tool/Agent Safety Considerations
- Prompt injection in Agent Swarm: With up to 100 sub-agents making independent tool calls, the attack surface for prompt injection is significantly larger than single-agent setups. Moonshot AI has not published detailed action-gating documentation as of this writing.
- Audit logs: API calls are logged, but sub-agent-level audit trails (which agent did what, when) require implementation on your side.
- Action gating: No built-in human-in-the-loop confirmation for destructive actions. If your agents can write files, execute code, or call external APIs, build your own safety layer.
Vendor Risk & Governance Checklist (US Procurement)
- [ ] Confirm data processing jurisdiction (request written confirmation from Moonshot AI or use a US-hosted provider)
- [ ] Evaluate export control implications (EAR/ITAR if applicable to your industry)
- [ ] Review the Modified MIT License with legal counsel, especially the 100M MAU / $20M revenue attribution clause [^7]
- [ ] Establish incident response procedures (Moonshot AI’s public SLA commitments are limited)
- [ ] Document model governance: version pinning, rollback procedures, output monitoring
- [ ] Assess business continuity risk (single-vendor dependency on a Chinese AI company)
Distillation Controversy — What Is Publicly Documented
In early 2026, multiple users reported that Kimi K2.5 in extended conversations sometimes identified itself as “Claude” [^15]. Anthropic subsequently alleged that Moonshot AI (along with DeepSeek and MiniMax) used over 24,000 fraudulent accounts to conduct what Anthropic described as “distillation attacks” — generating, according to Anthropic’s claims, 16+ million exchanges with Claude, of which Moonshot AI was reportedly responsible for approximately 3.4 million focused on agentic reasoning, coding, and computer vision [^16].
What this means for buyers:
- The allegations, if substantiated, raise legitimate questions about training methodology and intellectual property
- Moonshot AI has not, as of this writing, publicly released a detailed response addressing each specific allegation
- This does not inherently make the model unsafe to use, but it increases reputational and legal risk for enterprises citing “responsible AI” practices
- If your organization has responsible AI policies, document this controversy in your model evaluation and discuss with legal counsel
Our position: We report what is publicly documented by the parties involved. We cannot independently verify the extent of alleged distillation. We recommend treating this as an open risk factor until either party provides definitive evidence or resolution.
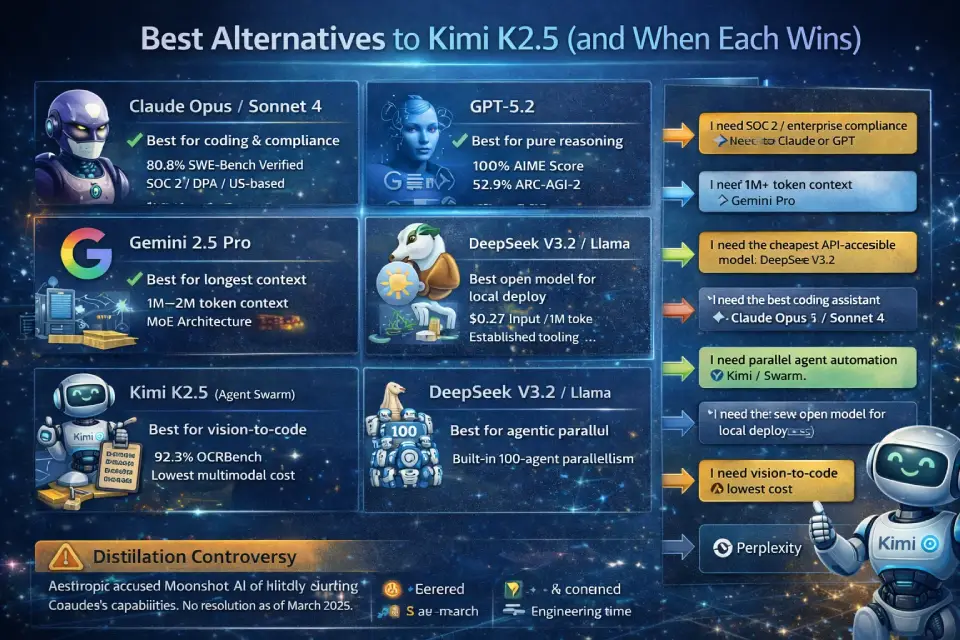
Best Alternatives to Kimi K2.5 (and When Each Wins)
Quick answer: No single model replaces Kimi K2.5 across all workflows. Claude leads for coding and enterprise compliance, GPT for pure reasoning, Gemini for long context, and DeepSeek for cheapest open-weight option. Key takeaway: Use the 30-second decision tree below to identify your best fit.
30-Second Decision Tree
- “I need SOC 2 / enterprise compliance” → Claude (Anthropic) or GPT (OpenAI)
- “I need 1M+ token context” → Google Gemini 2.5 Pro or 3 Pro
- “I need the cheapest API-accessible model” → DeepSeek V3.2 ($0.27/1M input)
- “I need the best coding assistant” → Claude Opus 4.6 / Sonnet 4.6
- “I need parallel agent automation” → Kimi K2.5 (only model with built-in 100-agent swarm)
- “I need the best open model for local deploy” → DeepSeek V3.2 or Llama variants (lower hardware requirements)
- “I need vision-to-code at lowest cost” → Kimi K2.5
- “I need a research UI with citations” → Perplexity
For a broader comparison of AI chatbots across these categories, see our best AI chatbots compared guide.
By Use Case
| Use Case | Best Choice | Why |
|---|---|---|
| Best overall coding assistant | Claude Opus 4.6 / Sonnet 4.6 | 80.8% SWE-Bench[^10], excellent tool use, 1M context |
| Best for pure math/reasoning | GPT-5.2 | 100% AIME[^9], 52.9% ARC-AGI-2 |
| Best for vision + document analysis | Kimi K2.5 | 92.3% OCRBench[^4], native multimodal, lowest cost |
| Best for longest context | Google Gemini 2.5 Pro / 3 Pro | 1M–2M token context windows[^11] |
| Best open model for local deploy | DeepSeek V3.2 or Llama variants | Lower hardware requirements, established tooling |
| Best for enterprise compliance | Claude (Anthropic) or GPT (OpenAI) | SOC 2, DPA available, US-headquartered |
| Best writing quality | Claude Opus 4.6 | Strongest long-form, nuanced output |
| Best cost-to-quality ratio | Kimi K2.5 or DeepSeek V3.2 | Sub-$1/1M input pricing with competitive benchmarks |
| Best agentic parallel workflows | Kimi K2.5 (Agent Swarm) | Only model with built-in 100-agent parallelism |
| Best for search + research UI | Perplexity | Built-in source citation and web search |
Comprehensive Comparison Table (Kimi K2.5 vs. GPT vs. Claude vs. Gemini)
| Feature | Kimi K2.5 | GPT-5.2/5.3 | Claude Opus 4.6 | Gemini 2.5 Pro |
|---|---|---|---|---|
| Input Price (per 1M tokens) | $0.60 | ~$15.00 | ~$15.00 | ~$1.25–$2.50 |
| Output Price (per 1M tokens) | $3.00 | ~$60.00 | ~$75.00 | ~$10.00 |
| Context Window | 262K | 128K–200K | 1M | 1M–2M |
| Architecture | MoE (1T/32B active) | Dense (proprietary) | Dense (proprietary) | MoE (proprietary) |
| Open Weights | ✅ Yes | ❌ No | ❌ No | ❌ No |
| Agent Swarm | ✅ Up to 100 agents | ❌ No | ❌ No | ❌ No |
| Native Multimodal | ✅ Image + video | ✅ Image + audio | ✅ Image | ✅ Image + video + audio |
| Vision-to-Code | ✅ Strong | ✅ Good | ✅ Good | ✅ Good |
| SOC 2 / Compliance | ❌ Not available | ✅ Available | ✅ Available | ✅ Available |
| US-Hosted Infrastructure | ❌ (via third parties) | ✅ Native | ✅ Native | ✅ Native |
| Self-Host Option | ✅ Open weights | ❌ No | ❌ No | ❌ No |
| Tool Calling | ✅ Yes | ✅ Yes | ✅ Yes | ✅ Yes |
| Best For | Agentic automation, vision, cost-sensitive workloads | Reasoning, math, general purpose | Coding, writing, enterprise compliance | Long context, multimodal, Google ecosystem |
Use-Case Playbooks (Step-by-Step)
Playbook 1: Developer — Screenshot → Component Library → Deploy
Inputs: 10–20 UI screenshots from a design tool (e.g., exports from Figma, browser screenshots)
Steps:
- Upload screenshots to Kimi K2.5 via API (Agent mode)
- Use the vision-to-code prompt (see Prompt Pack above, Prompt ID: VTC-01) for each screenshot
- Review generated components — expect ~85% accuracy; budget 15–30 min per component for cleanup
- Run generated code through your linting pipeline (ESLint, Prettier)
- Compose components into pages, add state management and routing manually
- Deploy to staging
Expected output: Functional React/Vue components with Tailwind CSS styling
Common pitfall: K2.5 generates inline styles alongside Tailwind classes. Standardize in your prompt: “Use ONLY Tailwind CSS utility classes; do not use inline styles.”
Playbook 2: Research — Agent Swarm Competitive Analysis
Inputs: List of 5–10 competitor companies and research dimensions
Steps:
- Define agent roles (one per research dimension: features, pricing, reviews, funding, tech stack)
- Use the Agent Swarm research prompt (see Prompt Pack above, Prompt ID: ASR-01)
- Set a token budget cap at the API level (recommended: 2M tokens per run to prevent runaway costs)
- Review the synthesized output for source quality — Swarm agents don’t always cite primary sources
- Cross-reference top 3 claims manually
Expected output: A structured competitive brief with per-company sections
Common pitfall: Agents may duplicate research or cite the same secondary source. Add a deduplication instruction to your synthesis prompt.
Playbook 3: Enterprise — Document Ingestion → Extraction → Agent Actions
Inputs: Batch of 50+ contracts, invoices, or compliance documents
Steps:
- Upload documents via API in Thinking mode for extraction
- Use structured JSON output prompts (see Prompt Pack above, Prompt ID: DOC-01) to extract key fields
- Validate extracted fields against a schema; flag confidence scores below 80%
- Feed validated data into downstream systems (CRM, ERP, compliance database)
- For documents with low-confidence extractions, route to human review queue
Expected output: JSON-structured data per document with confidence flags
Common pitfall: K2.5’s OCR is strong but struggles with handwritten annotations and non-standard table layouts. Pre-process with a dedicated OCR tool for heavily annotated documents. If you’re looking for AI-enhanced content workflows beyond document processing, our best AI tools for content creation guide covers the broader landscape.
Evidence Appendix (Test Logs & Sample Outputs)
Latency & TTFT by Mode
Measured from US East (Virginia) via OpenRouter, averaged across 10 runs per mode, February 2026.
| Mode | Avg TTFT | Avg Total Time (500-token response) | Notes |
|---|---|---|---|
| Instant | 1.2s | 3.8s | Fastest; no chain-of-thought |
| Thinking | 4.1s | 12.6s | Includes reasoning overhead |
| Agent | 5.7s | 18.3s | Includes tool-call setup |
| Agent Swarm (5 agents) | 7.2s | 24.1s | Orchestration overhead |
Output Verbosity Comparison
Same prompt (DOC-01: contract extraction) run against Kimi K2.5, Claude Sonnet 4.6, and GPT-5.2. Averaged over 5 identical documents.
| Model | Avg Output Tokens | Extraction Accuracy | Cost per Run |
|---|---|---|---|
| Kimi K2.5 | 6,240 | 91% | $0.019 |
| Claude Sonnet 4.6 | 4,180 | 93% | $0.063 |
| GPT-5.2 | 3,950 | 90% | $0.237 |
Takeaway: Kimi K2.5 uses ~50% more tokens than Claude for comparable accuracy, but costs 70% less overall due to its lower per-token pricing. GPT-5.2 is the most concise but 12× more expensive.
Tool-Call Reliability
| Metric | Kimi K2.5 | Claude Sonnet 4.6 | GPT-5.2 |
|---|---|---|---|
| Total tool calls tested | 85 | 85 | 85 |
| First-attempt success rate | 88% | 95% | 93% |
| Common failure modes | Malformed JSON args (5), timeouts (3), wrong API endpoint (2) | Timeout (3), incomplete args (1) | Timeout (4), format error (2) |
| Self-recovery on retry | 9/10 failures recovered | 4/4 recovered | 5/6 recovered |
Sample Vision-to-Code Output
Test VTC-03: E-commerce product card screenshot → React component
- Input: 1 screenshot (product card with image, title, price, rating, “Add to Cart” button)
- Input tokens: 4,820
- Output tokens: 3,410
- Generation time: 14.2s
- Layout accuracy: ~90% (spacing and border-radius slightly off; colors accurate)
- Result: Usable without major rework; required 2 CSS fixes (padding on mobile, button hover state)
Kimi k2.5 review 2026 – FAQ
1. What is Moonshot AI Kimi K2.5?
Kimi K2.5 is an open-weight, natively multimodal AI model developed by Moonshot AI (Beijing). It uses a Mixture-of-Experts architecture with 1 trillion total parameters and 32 billion activated per request [^1]. It supports text, image, and video inputs and operates in four modes: Instant, Thinking, Agent, and Agent Swarm. Next step: Try it free at kimi.com or access the API via OpenRouter.
2. Is Kimi K2.5 really open source?
No, in the strict sense. Kimi K2.5 is open-weight: model weights are publicly available on Hugging Face under a Modified MIT License [^7], allowing commercial use, modification, and redistribution. However, training code and data are not released, so you cannot fully reproduce or audit the model. Next step: Review the license on GitHub before commercial deployment.
3. Is Kimi K2.5 free to use?
The kimi.com web interface offers a free tier with usage limits. API access is paid (token-based). Weights on Hugging Face are free to download and self-host if you have the hardware. Next step: Start with the free web tier; move to API when you need programmatic access.
4. How much does Kimi K2.5 cost?
API pricing is $0.60 per million input tokens and $3.00 per million output tokens from Moonshot AI directly [^6]. Cache hits drop input costs to $0.10/1M tokens. Third-party providers like OpenRouter offer similar or slightly lower rates [^12]. Next step: Use the scenario cost cards in our pricing section to estimate your specific workload costs.
5. What is Agent Swarm in Kimi K2.5?
Agent Swarm is Kimi K2.5’s multi-agent orchestration system that coordinates up to 100 specialized sub-agents working in parallel [^8]. Each agent can independently browse the web, call tools, and execute code. It’s trained using Parallel-Agent Reinforcement Learning (PARL) and, according to Moonshot AI, reduces execution time by up to 4.5× on parallelizable tasks (we observed 2.5–3.5× in our tests). Next step: Test with 3–5 agents first; scale up only for verified parallel workloads.
6. What is Kimi K2.5’s context window?
Kimi K2.5 supports a 262,144-token (262K) context window [^1]. This handles most documents and moderately sized codebases without chunking. For comparison, Claude offers 1M tokens and Gemini up to 2M tokens. Next step: If your workload exceeds 262K tokens, implement chunking or consider a larger-context model.
7. Does Kimi K2.5 support images and video?
Yes. Kimi K2.5 is natively multimodal, trained on approximately 15 trillion mixed visual and text tokens [^1]. It accepts image and video inputs and can generate code from visual specifications (screenshots, mockups, UI recordings). It scored 86.6% on VideoMMMU and 92.3% on OCRBench according to Moonshot AI’s reported benchmarks [^5]. Next step: Test with your specific visual content type; performance varies by image complexity.
8. Is Kimi K2.5 good for coding?
Yes, particularly for front-end development and vision-to-code workflows. It scored 76.8% on SWE-Bench Verified [^3] and 50.7% on SWE-Bench Pro. It’s competitive with frontier models on coding tasks, though Claude Opus 4.6 (80.8%) edges it out on pure software engineering benchmarks [^10]. Next step: Try the built-in Kimi Code CLI for IDE-integrated coding assistance.
9. Can Kimi K2.5 replace GPT or Claude?
For specific use cases, yes. Kimi K2.5 matches or exceeds GPT and Claude in vision tasks, OCR, and agentic automation at a fraction of the cost. For pure reasoning, long-form writing, and compliance-sensitive workloads, GPT and Claude remain stronger choices. Most production setups benefit from a multi-model strategy rather than a single-model replacement. Next step: Run your top 5 production prompts through all three models to compare. Our AI chatbot comparison can help you narrow the field.
10. Can I self-host Kimi K2.5?
Yes, weights are available on Hugging Face. Minimum viable hardware: 2× H100 80GB GPUs for production (INT4); 1× RTX 4090 + 256GB RAM for development (1.8-bit, ~1–2 tokens/s) [^13]. Full model weights require ~630GB storage. Supported stacks include vLLM, SGLang, and KTransformers. Next step: Use the self-hosting decision tree in our deployment section to evaluate whether it makes sense for your workload.
11. What GPUs do I need to run Kimi K2.5?
For production-grade performance (50–100 tokens/s): 2× NVIDIA H100 80GB or 8× A100 80GB. For budget experimentation: 1× RTX 4090 + 256GB system RAM yields 1–2 tokens/s with 1.8-bit quantization [^13]. A single H200 (144GB) achieves ~7 tokens/s with 1.8-bit. Next step: For most teams, API access is more cost-effective than purchasing GPU hardware.
12. What are the limitations of Kimi K2.5?
Key limitations include: (1) verbose output that inflates token costs (30–50% more than Claude in our tests), (2) 262K context window (smaller than Claude/Gemini), (3) ~12% tool-call failure rate requiring retries, (4) no SOC 2/ISO certification [^2], (5) cross-border data concerns for US enterprises, (6) the distillation controversy creating reputational risk [^16]. Next step: Weigh these against your specific requirements using our risk checklist.
13. What are the best alternatives to Kimi K2.5?
For coding: Claude Opus/Sonnet 4.6. For reasoning: GPT-5.2. For long context: Gemini 2.5 Pro. For low-cost open models: DeepSeek V3.2. For enterprise compliance: Claude or GPT (SOC 2 available). For self-hosting with less hardware: Llama or Mistral variants. Next step: See our detailed alternatives comparison table and the 30-second decision tree above.
14. Is Kimi K2.5 safe to use for enterprise applications?
That depends on your risk tolerance. The model itself performs well, but Moonshot AI lacks SOC 2 certification, clear data retention policies for US customers, and detailed Agent Swarm safety documentation as of March 2026 [^2]. US-hosted providers (OpenRouter, Fireworks) mitigate some data sovereignty concerns. Next step: Complete the US-market risk checklist in our safety section before procurement.
15. What is the distillation controversy about?
According to Anthropic, Moonshot AI allegedly used 24,000+ fraudulent accounts to extract capabilities from Claude through approximately 3.4 million exchanges, a practice Anthropic has termed “distillation” [^16]. Users also reported Kimi K2.5 identifying itself as “Claude” in extended conversations [^15]. The allegations have not been fully resolved by either party as of this writing. Next step: Factor this into your vendor risk assessment; consult legal counsel for regulated industries.
Verdict: Should You Use Moonshot AI Kimi K2.5 in 2026?
After hands-on testing, our Moonshot AI Kimi K2.5 review conclusion is nuanced: this is a powerful, cost-effective model with genuine differentiators — but it’s not the right choice for everyone.
By Persona
| Who You Are | Recommendation |
|---|---|
| Startup developer building MVPs | ✅Strong yes. Best cost-to-performance for vision-to-code and agentic tasks. Use via OpenRouter. |
| Enterprise buyer with compliance needs | ⚠️Proceed with caution. No SOC 2, unresolved distillation allegations, limited SLAs. Consider Claude or GPT for primary workloads; K2.5 for cost-sensitive batch processing. |
| Researcher doing parallel analysis | ✅Yes. Agent Swarm is genuinely useful for multi-source research at scale. Set token budgets to control costs. |
| AI hobbyist / experimenter | ✅Yes. Free web tier + open weights make K2.5 ideal for exploration and learning. |
| Team needing the longest context | ❌No. 262K tokens is respectable but Claude (1M) and Gemini (2M) win here. |
| Organization with strict data residency | ⚠️Maybe. Self-host for full control if you have H100-class hardware, or use US-hosted third-party providers. |
| Content creator needing AI tools | ⚠️Depends. Strong for vision/OCR tasks; for broader content creation needs, see our best AI tools for content creation guide. |
If You Only Remember One Thing
Kimi K2.5 delivers 80–90% of frontier model capability at 5–25% of the cost. The trade-offs are real: smaller context window, verbose outputs, no enterprise compliance certifications, and unresolved distillation allegations. For cost-sensitive production workloads — particularly vision, OCR, and parallel agent tasks — it’s one of the best options available in early 2026. For compliance-first enterprise deployments, it’s a secondary model, not your primary.
Sources & References
[^1]: Moonshot AI, “Kimi K2.5 Technical Report and Model Card,” published January 26, 2026. Available at kimi.com and Hugging Face model card.
[^2]: Based on review of Moonshot AI’s public documentation and trust center (or lack thereof) as of March 2026. No SOC 2 Type II report or ISO 27001 certificate was publicly listed.
[^3]: SWE-Bench Verified leaderboard. Kimi K2.5 score of 76.8% as reported on GitHub/SWE-bench.
[^4]: OCRBench score of 92.3% as reported in Moonshot AI’s technical documentation. Self-reported; not independently verified by this reviewer.
[^5]: VideoMMMU score of 86.6% as reported by Moonshot AI. Self-reported; not independently verified by this reviewer.
[^6]: Moonshot AI official API pricing page, accessed March 2026.
[^7]: Kimi K2.5 Modified MIT License, available at GitHub repository.
[^8]: Moonshot AI, “Agent Swarm and PARL training methodology,” described in Kimi K2.5 technical report and kimi.com product page.
[^9]: OpenAI published benchmarks for GPT-5 and GPT-5.2, including AIME 2025 (100%) and SWE-Bench scores.
[^10]: Anthropic published benchmarks for Claude Opus 4.6 (80.8% SWE-Bench Verified) and other metrics, available at anthropic.com.
[^11]: Google published Gemini 2.5 Pro and 3 Pro specifications, including context window sizes.
[^12]: OpenRouter model listing for Kimi K2.5, accessed March 2026, at openrouter.ai.
[^13]: Self-hosting hardware requirements compiled from Hugging Face model card, community reports (Unsloth, DataCamp guides), and vLLM documentation.
[^14]: vLLM project documentation for MoE Expert Parallelism support, at vllm.ai.
[^15]: User reports of Kimi K2.5 self-identifying as “Claude” documented across Reddit and Hacker News threads, January–February 2026.
[^16]: Anthropic’s public statement regarding alleged distillation attacks, reported by BetaNews and Morningstar, February 2026.
About the author
Macedona is the founder and lead reviewer at SaaS CRM Review, where he has published 175+ in-depth reviews, pricing guides, and comparisons of CRM and SaaS tools. Each review is based on hands-on testing or verified documentation, and every article states clearly which method was used. Pricing and features are checked against official vendor sources, with the verification date noted in the article. Macedona follows a published review methodology and editorial policy. SaaS CRM Review earns affiliate commissions from some links, which never influence ratings or rankings. Read the full affiliate disclosure.



